

Data sensitivity and security should be top of mind for any organization that is considering selling data. However, these considerations should not prohibit an organization from participating in the data economy.
Misconceptions about data sensitivity and security prevent many organizations from legitimately considering data sales. These unnecessary, perceived hurdles could be easily addressed with thoughtful product structure.
When structuring a data product, Vendors should assess which data need to be excluded for competitive reasons or legal liability. Vendors will make trade-offs between richness of the data set and the price they will be able to charge.
The following sections examine two key elements of compliance:
- Personally Identifiable Information (PII)
- Sensitive corporate information.
Personally Identifiable Information (PII)

The definition of PII varies wildly from country to country. For example, the EU has very strict laws about PII and has adopted a very broad definition of it, generally more so than in Asia.
Vendors need to understand the PII laws in place where their data are collected and located. Vendors should consult with experts before collecting any PII data, regardless of their intention to sell data locally or for export.
Please consult the following resources for a brief overview of privacy standards:
- Privacy Law - Wikipedia
- Data Protection Laws of the World – DLA Piper
- International Cryptography Regulation and the Global Information Economy - Northwestern Journal of Technology and Intellectual Property
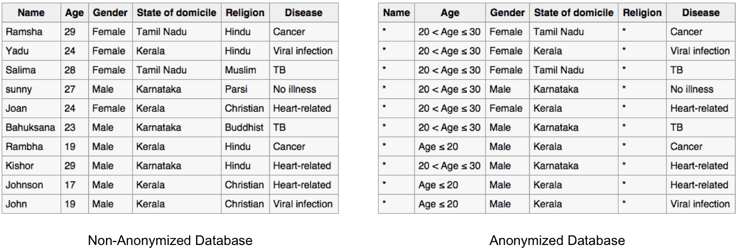
To ensure that human-focused data sets comply with PII standards, Vendors need to anonymize the entries. To do so, Vendors should consider two different courses of action:
- K-anonymity and
- generalization

K-anonymity: The U.S. Federal Trade Commission generally defines K-anonymity in the following way: "Given person-specific, field-structured data, [K-anonymity] produces a release of the data with scientific guarantees that the individuals who are the subjects cannot be re-identified, while the data remains practically useful." For example, if a collection of records is from a certain zip code, Vendors should ensure that more than one record from any given zip code is included in the data set. This way, it is quite difficult to identify a single record and tie it back to an individual.
Generalization: In data generalization, specificity is removed. In order to remove this specificity, categories are established to take the place of precise figures. The data is then masked by assigning each record to one of the pre-defined categories.
The anonymized table below uses generalization to obscure the age of the patients and uses K-anonymity to remove name and religious information.
Sensitive Corporate Information
 / Foter / CC BY") Technology & Channel Considerations
Technology & Channel Considerations
DataStreamX holds the belief that data is among an organization’s most valuable assets. Thus, organizations need to be diligent about protecting their data assets.
The practice of selling data has existed for decades, with proven methods to grant access to data while protecting sensitive corporate information. With such controls in place, Vendors should be excited for their data to enable innovation and generate “bolt-on revenue” to assist their operations.
If Vendors use channel partners, like DataStreamX to help monetize their data, they should be certain that these companies will provide features such as dashboards, restricted access capabilities and on-demand reports. Further, they need make sure that they can have insight into who the parties are that are interested in purchasing and using data products before accepting a sale.
Information Management
 “Raw” data is the most valuable type of data a Vendor can offer. An example of raw data for a retailer would be shopping baskets with final prices, order numbers, etc. This data provides deep insights into a company’s performance and correlations between products. As such, it is generally seen as a very premium product. However, this may be too sensitive to even provide to internal stakeholders.
“Raw” data is the most valuable type of data a Vendor can offer. An example of raw data for a retailer would be shopping baskets with final prices, order numbers, etc. This data provides deep insights into a company’s performance and correlations between products. As such, it is generally seen as a very premium product. However, this may be too sensitive to even provide to internal stakeholders.
Vendors concerned about protecting sensitive corporate information can employ any of the following techniques and still attract global buyers and command premium prices for their data sets:
Indices: Insights derived from indices based on the same underlying data are still quite valuable. The Case-Shiller indices, for example, provide extremely important insights into the U.S. real-estate market. These indices are so telling that financial products such as futures and options are structured and traded based on them.
Proxies: Vendors can also consider proxy variables to provide insights that their target customers are seeking to obtain. Examples include using a zip code in place of home address or using MSRP in place of final selling price. Percentages are also helpful in breaking down population behavior and generalizing trends over time. These time comparison trends also create a higher likelihood for purchasing ongoing data subscriptions.
Separation: Vendors can also consider slicing their data into segmented products that address the specific needs of the data buyers, but don’t reveal all of the competitive intelligence. For example, a large retailer could divide and sell their data by different product categories or geographies. In this manner, if competitive Buyers actually wanted to get full visibility into the Vendor’s health, they would have to spend a tremendous amount of money to do so.
When employing any of these techniques, Vendors should ensure that each is properly communicated to potential buyers so they can understand what is contained within the underlying data.
In general, Vendors need to make note of any changes or manipulations that have been done to the data so that the end users will understand the implications on analysis.
To learn more, download the whitepaper, “The Practical Guide to Selecting & Structuring Data Products”

Missed the first part of the series? See "Structured to Sell - Part 1 of 4: Data Monetization Motivations" to help your organization understand how to sell data.